SYCL™ Performance for Nvidia® and AMD GPUs Matches Native System Language
06 April 2023
Benchmarks executing workloads using DPC++, oneAPI’s implementation of SYCL achieves close to native performance on Nvidia and AMD GPUs, when comparing to the same benchmarks run with CUDA®* and HIP*, respectively.
By Ruyman Reyes Castro, CTO, Codeplay
At Codeplay we’ve worked to advance heterogeneous programming for years now, including leading and contributing to Khronos Group’s open standard SYCL programming model. Our focus from the start has always been: How do we enable heterogeneous hardware from multiple vendors with minimal effort from developers? Delivering productivity and performance in a multi-vendor world can be difficult. Every accelerator vendor uses hardware features to differentiate themselves from the rest, and they usually expose these features using their native (and typically proprietary) programming models. When designing SYCL, we focused on an industry standard way to leverage all the various hardware features from all vendors in the market for ease and accessibility, ultimately driving innovation and choice. This enables SYCL applications to be truly portable across multiple vendors’ architectures whilst allowing for custom architecture tuning, and bringing a stable solution for the long term - so software investments value isn’t lost when moving to new generations of hardware.
It's easy to be a skeptic - and at times, I’ve been one myself, especially when native system programming is entrenched and works well for single architecture systems. With oneAPI and SYCL, there is clear value extending across different types of workloads. More companies, organizations and supercomputing centers are adopting oneAPI not only for Intel architectures, but also on other architectures including NVIDIA and AMD GPUs. We know significant portability and productivity benefits are there when you can use a single codebase across multiple vendors’ architectures. We’re at the beginning - but real benchmarks and numbers are coming to light demonstrating higher or comparable performance of SYCL workloads optimized by oneAPI1 running on NVIDIA and AMD GPUs vs. native system language (CUDA* for NVIDIA or HIP* for AMD).
SYCL: Portable with Performance
SYCL is a C++-based parallel programming language running on multiple accelerators (CPU, GPU, FPGA) from Intel, AMD, NVIDIA and other vendors in the industry. SYCL is proven to be portable across multiple compute architectures and provides performance comparable to native and established programming environments on those compute units. There is no “magic” behind SYCL, it’s proven technology, with concepts similar to that of CUDA, TBB and other parallel programming models. Developers write their code using standard concepts, such as memory allocations, queue submissions and kernels for performance critical parts of the code. A SYCL implementation, like DPC++, will put all the pieces together on an application that you can run on multiple systems from a single compiler invocation. All this is done using only standard C++ code with no proprietary syntax.
Performance Benchmarks: SYCL vs CUDA and HIP
Performance is a critical aspect when working with xPU acceleration, and we’ve put a lot of effort into making sure that oneAPI extracts as much performance from targeted hardware as it possibly can at this point in time. Several benchmark results show that we can match native performance in many cases, and we continue to work on this. Our experience is that, in the vast majority of use cases, there is no fundamental aspect of the programming models that would cause a performance difference, and the majority of the performance issues are due to performance tuning of different values (e.g. CUDA block sizes vs local work groups in SYCL) or toolchain options that impact code generation, such as inlining or unrolling, which can be very easily tuned. Thanks to SYCL it is possible to maintain a single source that can be adapted to multiple targets for performance. If you want to use hardware features from an specific vendor you still can using extensions, and if you want to use the existing vendor optimized libraries, SYCL offers you ways to interop with them while keeping your code neutral. To reiterate what was previously stated here there is no magic, just open standards and strong community involvement in building a healthy ecosystem.
Figure 1 (below) shows the performance comparison of a CUDA code migrated to SYCL using the open source SYCLomatic tool to SYCL and then compiled and executed on the same Nvidia GPU using the DPC++/C++ CUDA backend. This is a good example of a code migration where the migration that is almost transparent, and the resulting SYCL code performs comparably to the original CUDA one. The source code can be found in the GitHub repo along with scripts so you can try this out and experiment with the project yourself.

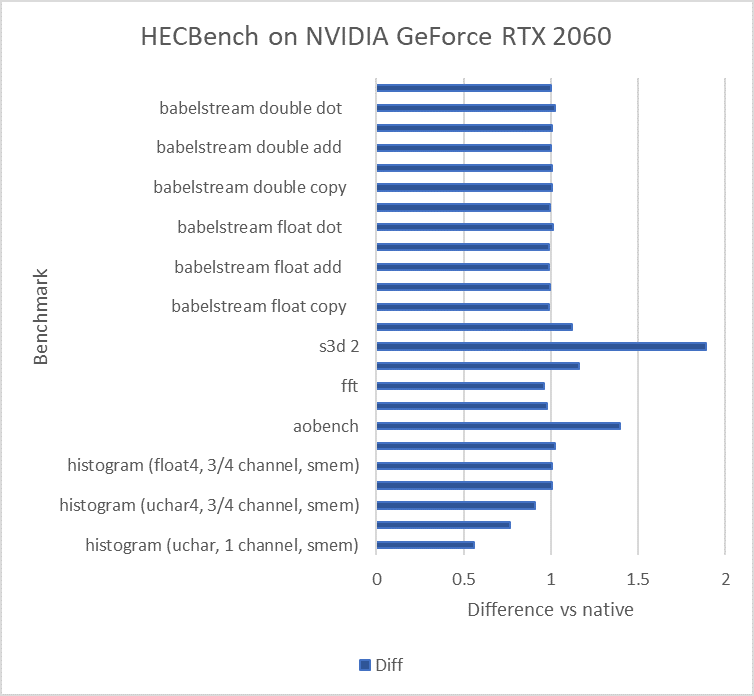
Figure 2 which follows, shows performance of a representative selection of benchmarks from the open source HeCBench project, containing various benchmarks from different application domains, comparing DPC++ with native CUDA. Most of these benchmarks show comparable performance of SYCL versus native CUDA. In some cases, the SYCL code is faster and in some cases slower, where there are still opportunities to fine tune the performance.
Next are performance benchmarks comparing algorithms/data sets spanning many industry domains written using
SYCL vs implementations in native system languages - CUDA and HIP on NVIDIA and AMD GPUs, respectively.
Each data set was characterized, analyzed and tuned for each compute architecture and its native language.
Figure 3 shows 10 workloads comparing SYCL performance to CUDA on an Nvidia H100* system, where for six
workloads SYCL performance is greater or equal to CUDA, and the rest of the workloads where the performance
difference is negligible. Figure 3 Relative performance comparison of select data sets running in SYCL vs CUDA on Nvidia-A100.
In six workloads, SYCL performance is greater or equal to CUDA. The performance difference for the other
workloads is insignificant.2
Figure 3 Relative performance comparison of select data sets running in SYCL vs CUDA on Nvidia-A100.
In six workloads, SYCL performance is greater or equal to CUDA. The performance difference for the other
workloads is insignificant.2
Figure 4 shows 9 workloads where SYCL performance is comparable to HIP on an AMD Instinct* MI100 system. Variances for both benchmark tests comparing SYCL to CUDA and HIP are due to maturity and capabilities of different compiler and runtime toolchains.

Multiarchitecture Supercomputing Leads the Way
oneAPI is helping multiarchitecture-powered supercomputers advance to exascale and zettascale. Argonne rolled out early performance numbers using Intel® Data Center GPU Max Series, the University of Cambridge and Texas Advanced Computing Center’s Frontera Supercomputer are also leading some big oneAPI supported projects. HPCWire’s article: SYCL Progress and Performance from the U.S. Exascale Computing Project (ECP)’s community birds-of-a-feature (BOF) days shared programming insights from Argonne Leadership Computing Facility (ALCF) on Aurora, Oak Ridge Leadership Computing Facility (OLCF) on the first U.S. exascale system Frontier, National Energy Research Scientific Computing Center (NERSC) on Perlmutter, and more.
For workloads that measure time (defined as time spent on device and time used in data transfer between host and device), the ones selected include domains such as HPC, big data compute, machine learning and deep learning, ray tracing, and crypto/bit-mining. Each measurement was run 10 times; the first measurement is discarded and then the average is taken. In most cases, better performance was attributed mainly to efficient code generation by the compiler and the time differences in setup/initialization.
Conclusion
We see from these results that SYCL is highly performant on Nvidia and AMD devices and performs comparably to native CUDA or HIP code for diverse workloads. The SYCL and oneAPI development environment and compilers, tools, libraries are highly efficient and competitive. Available code migration tools like SYCLomatic simplify porting code from CUDA to SYCL.
As multiarchitecture, multivendor programming and use of oneAPI and SYCL expands, real-world usages by some of the premier supercomputers and ported applications are blazing the trail (more below). No doubt many more performance comparisons ahead, and we look forward to seeing them and working with the ecosystem to advance open, standards-based heterogeneous computing for all.
If you would like to try using SYCL on NVIDIA and AMD GPUs yourself, download the oneAPI for NVIDIA and AMD GPUs from Codeplay’s developer website.
More Resources
- oneAPI
- oneAPI plugins for Nvidia and AMD GPUs
- Migrate CUDA code to SYCL tools: open source SYCLomatic project | Intel® DPC++ Compatibility Tool
Notices and Disclaimers
1 oneAPI’s implementation in SYCL is Data Parallel C++ (DPC++)
2 Fig. 3 Relative Performance: Nvidia SYCL vs. Nvidia CUDA on Nvidia-A100 – Testing Date: Performance results are based on testing by Intel as of Aug. 15, 2022 and may not reflect all publicly available updates. Configuration Details and Workload Setup: Intel® Xeon® Platinum 8360Y CPU @ 2.4GHz, 2 socket, Hyper Thread On, Turbo On, 256GB Hynix DDR4-3200, ucode 0x000363. GPU: Nvidia A100 PCIe 80GB GPU memory. Software: SYCL open source/CLANG 15.0.0, CUDA SDK 11.7 with NVIDIA-NVCC 11.7.64 cuMath 11.7, cuDNN 11.7, Ubuntu 22.04.1. SYCL open source/CLANG compiler switches: -fsycl-targets=nvptx64-nvidia-cuda, NVIDIA NVCC compiler switches: -O3-gencode arch=compute_80, code=sm_80. Represented workloads with Intel optimizations.
3 Fig. 4 Relative Performance: AMD SYCL vs. AMD HIP on AMD Instinct MI100 Accelerator – Testing Date: Performance results are based on testing by Intel as of Aug. 15, 2022 and may not reflect all publicly available updates. Configuration Details and Workload Setup: Intel® Xeon® Gold 6330 CPU @ 2.0GHz, 2 socket, Hyper Thread Off, Turbo On, 256GB Hynix DDR4-3200, ucode 0xd000363. GPU: AMD Instinct MI100, 32GB GPU memory. Software: SYCL open source/CLANG 15.0.0, AMD RoCm 5.2.1 with AMD-HIPCC 5.2.21152-4b155a06, hipSolver 5.2.1, rocBLAS 5.2.1, Ubuntu 20.04.4. SYCL open source/CLANG compiler switches: -fsycl-targets=amdgcn-amd-amdhsa-Xsycl-target-backend-offload-arch=gfx908, AMD-HIPCC compiler switches: -O3. Represented workloads with Intel optimizations.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See configuration disclosure for details. No product or component can be absolutely secure. Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
