User-driven Kernel Fusion
20 March 2023
Introduction
The overhead linked to offloading work to an accelerator can be problematic, especially for short-running device kernels. Fusing multiple smaller kernels into one can be a solution to this problem, but manual implementation of fused kernels is tedious work, as it needs to be repeated for each potential combination of kernels. Codeplay have therefore developed an extension for the SYCL standard for user-driven, automatic kernel fusion. If you want to learn how to instruct the SYCL runtime to perform kernel fusion automatically for you, look no further and dive into this blog-post, which explains the extension and demonstrates its use on a simple example.
Motivation
Today, many computational tasks require heterogeneous computing for their efficient solution. Accelerators such as GPUs can significantly reduce time-to-solution, for instance, by solving the task at hand for many items in parallel, and programming models such as SYCL have given developers easy access to the power of their GPU.
However, offloading work to an accelerator does not come for free: Every kernel launch on an accelerator carries some runtime overhead for tasks such as synchronization and data-transfer. While the exact amount of overhead depends on the system configuration, this overhead can eat up all the speedup gained by execution on the accelerator. This effect is particularly pronounced for a sequence of very short-running device kernels, as shown in the following figure.
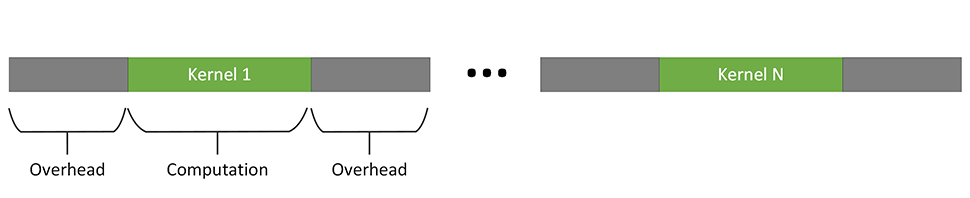
One solution to help achieve the benefit of accelerators is to fuse multiple smaller kernels into a single, larger kernel. The fused kernel is better able to amortize the overhead for device kernel launch, due to the better compute/overhead ratio, as shown in the following picture.
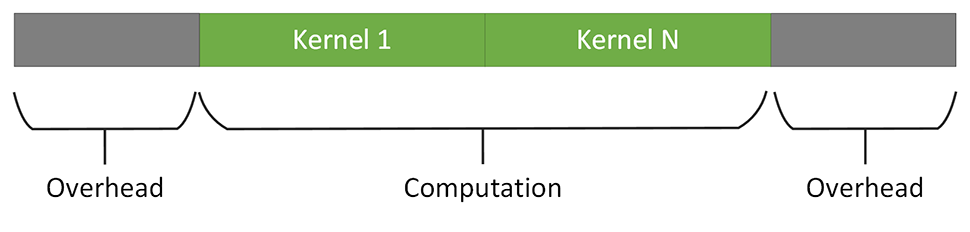
Yet, manually creating an implementation for the fused kernel is a tedious and error-prone task. The resulting fused kernel can also be less re-usable than the individual smaller kernels it is composed of.
Extension
To overcome this problem and lift the burden of manually implementing a fused kernel from the user, Codeplay have developed an extension for the SYCL programming model.
The extension still lets the user decide when and which kernels to fuse, but it completely automates the creation of the fused kernel implementation in the SYCL runtime. Through its simple design, the extension empowers users to enable fusion of device kernels in their application with only minimal code changes.
The basic idea of the extension API is quite simple: A SYCL queue is put into
something we will refer to as “fusion mode” through a new API function. While
the queue is in fusion mode, the kernels that are submitted to this queue
are not passed to the SYCL runtime scheduler for execution right away, but
rather collected in a list of kernels that are to be fused. Once the list
contains all the kernels the user wants to fuse, fusion mode is ended and fusion
is completed through another new API function. Completing the fusion means that
the SYCL runtime will programmatically create a new fused kernel from the list of
kernels collected in fusion mode and execute that kernel with the arguments
originally passed to the individual kernels.
The creation (i.e. compilation) of the fused kernel happens entirely at runtime of the SYCL application (“online”) through a small just-in-time (JIT) compiler. The static compilation step of the SYCL application is not modified by this extension.
More concretely, to integrate kernel fusion into an existing SYCL application, the following steps need to be performed:
- When creating the SYCL
queue, the additional propertysycl::ext::codeplay::experimental::property::queue::enable_fusionneeds to be passed to the property list of the queue, e.g.:queue q{gpu_selector{}, {ext::codeplay::experimental::property::queue::enable_fusion()}}; - Create a
fusion_wrapperobject to gain access to the fusion API, e.g.:ext::codeplay::experimental::fusion_wrapper fw{q}; - Before submitting the first kernel that should be part of the fused kernel to
the
queue, enter fusion mode through a call tostart_fusion:fw.start_fusion(); - Submit kernels to the
queueas you would normally do, no modification to this code is necessary to use the fusion extension. - Once you have submitted all the kernels that should be part of the fused
kernel, leave fusion mode and instruct the runtime to create and execute the
fused kernel through a call to
complete_fusion.fw.complete_fusion();
Alternatively, if you decide you don’t want to go ahead with the fusion and
would rather prefer to execute the kernels as individual kernels, you can call
cancel_fusion instead of complete_fusion. In that case, the fusion mode is
also ended, but the kernels in the fusion list are simply passed to the SYCL
runtime scheduler and executed one-by-one.
The API extension described here is part of DPC++ nightly release 2023-02-04 onwards. The usage example in the next section will give the full picture on how to integrate the extension into an application and also demonstrates how few changes are actually required to integrate kernel fusion into an existing SYCL application code.
Usage Example
The following example of a simple SYCL application will serve as the running example for this post.
#include <sycl/sycl.hpp>
using namespace sycl;
constexpr size_t dataSize = 100'000'000;
int main() {
// [...] Data initialization
queue q{ext::codeplay::experimental::property::queue::enable_fusion{}};
{
buffer<float> bIn1{in1.data(), range{dataSize}};
buffer<float> bIn2{in2.data(), range{dataSize}};
buffer<float> bIn3{in3.data(), range{dataSize}};
buffer<float> bIn4{in4.data(), range{dataSize}};
buffer<float> bOut{out.data(), range{dataSize}};
buffer<float> bTmp1{range{dataSize}};
buffer<float> bTmp2{range{dataSize}};
buffer<float> bTmp3{range{dataSize}};
ext::codeplay::experimental::fusion_wrapper fw{q};
fw.start_fusion();
// tmp1 = in1 * in2
q.submit([&](handler &cgh) {
auto accIn1 = bIn1.get_access(cgh);
auto accIn2 = bIn2.get_access(cgh);
auto accTmp1 = bTmp1.get_access(cgh);
cgh.parallel_for<class KernelOne>(
dataSize, [=](id<1> i) { accTmp1[i] = accIn1[i] * accIn2[i]; });
});
// tmp2 = in1 - in3
q.submit([&](handler &cgh) {
auto accIn1 = bIn1.get_access(cgh);
auto accIn3 = bIn3.get_access(cgh);
auto accTmp2 = bTmp2.get_access(cgh);
cgh.parallel_for<class KernelTwo>(
dataSize, [=](id<1> i) { accTmp2[i] = accIn1[i] - accIn3[i]; });
});
// tmp3 = tmp2 * in4
q.submit([&](handler &cgh) {
auto accIn4 = bIn4.get_access(cgh);
auto accTmp2 = bTmp2.get_access(cgh);
auto accTmp3 = bTmp3.get_access(cgh);
cgh.parallel_for<class KernelThree>(
dataSize, [=](id<1> i) { accTmp3[i] = accTmp2[i] * accIn4[i]; });
});
// out = tmp1 - tmp3
q.submit([&](handler &cgh) {
auto accTmp1 = bTmp1.get_access(cgh);
auto accTmp3 = bTmp3.get_access(cgh);
auto accOut = bOut.get_access(cgh);
cgh.parallel_for<class KernelFour>(
dataSize, [=](id<1> i) { accOut[i] = accTmp1[i] - accTmp3[i]; });
});
fw.complete_fusion();
q.wait();
}
process_further(out);
return 0;
}
Each individual kernel in the example is only performing a single element-wise operation and is relatively small, but they form a graph with a total of four calls, where the outputs of one kernel serve as input to another. This kind of sequence of simple arithmetic kernels is for example often found in neural network workloads, e.g. GPT (where this sequence occurs).
Compared to the base application, only the four line changes discussed above need to be performed to enable kernel fusion for this application, fusing the sequence of four kernels into a single kernel.
When comparing the performance with and without kernel fusion, we can observe a reduction in application runtime from ~353ms to about 339ms1. Not bad considering the fact we only had to change four lines of code! And, before you get disappointed, later on, we will demonstrate how kernel fusion can lead to much bigger performance improvements.
Correctness and Profitability Considerations
Now that we have seen how to use the extension, we should also discuss when to use it.
The extension leaves the decision which kernels to fuse completely to the user, who therefore must assess two important criteria:
- Correctness: make sure the fused kernel will still yield the correct result
- Profitability: to be sensible, the fusion should also yield better performance
For correctness, the most important aspects are potential dataraces and synchronization issues.
In non-fused execution, there is an implicit global barrier between the sequential execution of two SYCL device kernels. That means that all work-items in the second kernel can see all the updates made to data by all the work-items in the first kernel.
As there is in general no device function for device-wide synchronization for device code which the JIT compiler could insert into the fused kernel, this device-wide synchronization is not possible in the fused kernel.
As long as work-items in the originally second kernel only depend on updates from work-items in the same work-group in the first kernel, no data-race will occur and the JIT compiler will automatically insert a work-group barrier to guarantee intra-work-group synchronization.
However, if any work-item in the second kernel depends on updates made by work-items in a different work-group in the first kernel, this will lead to synchronization issues and potential violations of read-after-write (RAW), write-after-read (WAR) and write-after-write (WAW) dependencies in the fused kernel. Users must ensure that no such inter-work-group synchronization is required by the kernels participating in kernel fusion by inspecting the access pattern of device kernels prior to adding them to a fusion list.
An example of two kernels that rely on the implicit device-wide synchronization is given in the following code snippet.
q.submit([&](handler &cgh) {
auto accIn1 = bIn1.get_access(cgh);
auto accIn2 = bIn2.get_access(cgh);
auto accTmp = bTmp.get_access(cgh);
cgh.parallel_for<class KernelOne>(
nd_range<1>{range<1>{dataSize}, range<1>{8}}, [=](item<1> i) {
size_t index = (i.get_range(0) - i) - 1;
accTmp[index] = accIn1[i] + accIn2[i];
});
});
q.submit([&](handler &cgh) {
auto accTmp = bTmp.get_access(cgh);
auto accIn3 = bIn3.get_access(cgh);
auto accOut = bOut.get_access(cgh);
cgh.parallel_for<class KernelTwo>(
nd_range<1>{range<1>{dataSize}, range<1>{8}},
[=](id<1> i) { accOut[i] = accTmp[i] * accIn3[i]; });
});
In the second kernel in this example, work-item i needs the result of the
work-item with index dataSize - i in the first kernel. For most of the
work-items, this means synchronization with a work-item from outside their own
work-group due to the work-group size of 8.
But even if fusion is legal and the fused kernel will yield correct results, it is not always beneficial with regard to performance to perform fusion. For example, an increased register pressure in the fused kernel can lead to worse performance with fusion. While there is no easy and general rule-of-thumb to decide when it is profitable to perform fusion, the extension API is simple enough to integrate into an existing application and simply benchmark performance with and without fusion.
Some additional guidelines on how to assess whether kernel fusion will improve the performance of the application will be given in the next section.
In the usage example above, we have seen a noticeable, but rather small speedup1 through kernel fusion, which leaves us wondering: Can we do even better, i.e. can the fused kernel provide even better performance?
Background on Dataflow & Internalization
As it turns out, we can: By optimizing the dataflow between the individual kernels that make up the fused kernel, we can further improve performance significantly1.
If two (or more) kernels collaborate to produce a final result, there is only one way to communicate intermediate results produced by one kernel and consumed by one of the subsequent kernels: The kernel producing the intermediate result must store it to global memory so that the next kernel can load it from global memory. The lifetime of all other memories that can be written by a kernel (registers/private memory and local memory) is bound to the execution time of the kernel, so those can’t be used to pass data between kernels, even though access to these memories is significantly faster than access to global memory.
However, with kernel fusion, the two kernels execute as a single fused kernel, so using private and local memory is back on the table. So, in the fused kernel, instead of having one of the regions of the fused kernel (corresponding to one of the kernels being fused) write its results to global memory, the results can be stored in much faster private or local memory so that a subsequent region of the fused kernel (corresponding to a subsequent kernel) can access them there instead of performing expensive reads from global memory. In this article, we refer to this process as internalization, as it makes dataflow internal to the fused kernel.
If we return to our usage example above, we can
easily identify some dataflow that can be internalized. All the temporary results
stored to the buffers bTmp1, bTmp2, and bTmp3 could be internalized. After
execution of the fused kernel completes, the application does not access those
intermediate results anymore, only the final result in out is still
required by the host application for futher processing.
How to automatically internalize dataflow with the extension
Similar to fusion itself, the kernel fusion SYCL extension aims to provide an easy-to-use mechanism for users to instruct the SYCL runtime to automatically perform the internalization of dataflow.
For the JIT compiler to be able to perform the internalization, three prerequisites must be fulfilled:
- The accessor used for writing by the first kernel must refer to the same buffer as the accessor used for reading by the second kernel.
- The data produced by the first kernel must not be required by a third kernel which does not participate in fusion.
- Internalizing the dataflow to either private or local memory must not cause data-races or incorrect behavior.
The first prerequisite can be established by the SYCL runtime and the JIT compiler automatically and does not need any user input.
The second prerequisite cannot be established by the SYCL runtime, because that
would require the SYCL runtime to predict the future, as the third kernel using
the data from the first kernel might not even have been submitted by the
application when the call to complete_fusion happens. Therefore, this condition
requires users input.
The third condition currently also still requires users input, although this might change in the future when the JIT compiler gains more advanced analysis capabilities. For internalization to private memory to be legal, memory locations written to by a work-item in a kernel must only be accessed by the same work-item in subsequent kernels. For internalization to local memory, this condition can be relaxed: memory locations written to by a work-item in a kernel must only be accessed by work-items in the same work-group in subsequent kernels.
The user can use their knowledge of the application and kernel implementation to tell the SYCL runtime whether and which of the two internalizations is legal.
The SYCL extension combines the answer to the second and third prerequisite, to
make it easier for users to specify the desired internalization. By specifying
the property sycl::ext::codeplay::experimental::property::promote_private, the user allows the
SYCL runtime and JIT compiler to perform internalization to private memory for a buffer. The property
sycl::ext::codeplay::experimental::property::promote_local works analogously,
but for internalization to local memory.
Both properties can either be added to the property list of a buffer upon construction to internalize that buffer, or it can be specified on accessors to give more fine-grained control, in which case it must be specified on all accessor referring to the same underlying buffer. If the property is missing on one of the accessors, the JIT compiler will not perform internalization.
As discussed above, in our usage example, bTmp1, bTmp2, and bTmp3 are good
candidates for internalization. Their content is not accessed by the application
after the fused kernel completes execution, and the work-items in the
application are completely independent from each other, so they meet all
prerequisites for internalization in private memory.
In this case, the fastest way to instruct the runtime to perform the internalization is to attach the property to the buffers directly.
In our example, this means changing the definition of the three buffers to the following.
buffer<float> bTmp1{
range{dataSize},
{sycl::ext::codeplay::experimental::property::promote_private{}}};
buffer<float> bTmp2{
range{dataSize},
{sycl::ext::codeplay::experimental::property::promote_private{}}};
buffer<float> bTmp3{
range{dataSize},
{sycl::ext::codeplay::experimental::property::promote_private{}}};
With this simple change to the code, the JIT compiler will internalize the dataflow instead of storing/loading intermediate results to/from the global memory in the buffers.
If we repeat the performance evaluation from above, we can observe that the runtime drops from initially ~353ms (without fusion) to about 272ms, which is equivalent to a reduction in runtime by more than 22%1.
If we execute the same sequence of kernels multiple times, which is quite common in neural networks for instance, we can observe even more performance improvement. When we execute the sequence of kernels in our example inside a loop, and focuse on the iterations from the second iteration onwards, we can observe a reduction in runtime from ~230ms to about 88ms per iteration, corresponding to a speedup by factor 2.6x1.
Why is that? The reduction for the non-fused execution comes from the caching of device binaries in the device driver (so no translation from SPIR-V to device binary must happen from the second iteration onwards).
The explanation for the fused case is similar: Performing kernel fusion at runtime in the JIT compiler of course also carries some overhead. As the JIT compiler also employs a caching mechanism, so no expensive JIT compilation must happen from the second iteration onward, and the translation of SPIR-V to device binary for the fused kernel also gets cached in the device driver.
So the kernel fusion extension can shine even more when applied to a repeated sequence of kernels.
Outlook
This blog post gave a gentle introduction to the SYCL extension for kernel fusion by Codeplay. The extension allows to easily integrate kernel fusion into an existing SYCL application and allows to avoid the high overhead cost of small device kernels by automating the process of kernel fusion based on user instructions.
The extension is currently still experimental, and Codeplay seeks to improve the API and capabilities of the extension in the future. The API is therefore expected to evolve in the future, so keep an eye on the extension proposal, where you can also find information on the finer details on semantics of the extension.
With the extension, it is now possible to compose a SYCL application from multiple smaller kernels and still get similar performance as if the developer had spent a lot of effort on creating a single kernel from the different parts of the application. In the future, this could facilitate a new programming style for parallel and heterogeneous programming using a library of smaller kernels to build larger applications, allowing reuse of these modular component kernels in different applications.
Disclaimer
1Experiments performed on 07/02/2023 by Codeplay, with Intel Core i7-6700K, Ubuntu 20.04.5 LTS, Linux kernel 5.15, and OpenCL driver version 2022.14.10.0.20_160000.xmain-hotfix.
DPC++ nightly version 2023-02-04 (git commit
aa69e4d9b86c9f0e1cb109d7f6870584f3328908) was used for measurements.
Performance varies by use, configuration and other factors. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation. Intel, the Intel logo, Codeplay and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
