Edinburgh Uni Formula Student's Journey from CUDA® to SYCL™
17 October 2022

I am a member of the EUFS (Edinburgh University Formula Student) driverless team and the planning and control lead for this year. EUFS is a purely student lead team where we build an autonomous racing car with the goal of competing in the Formula Student UK competition. So far, we have been on a 5-year winning streak, and we are hoping to extend this streak next year. Codeplay has provided support to our team with sponsorship and technical mentoring for the past 3 years.
One of the tasks we must be able to perform at the competition is driving the race car around an unknown track for 10 laps. The track is laid out with cones and whichever team manages to go around the track fastest and hit the least cones scores the most points. To efficiently tackle this problem, we chose to split the task into two stages. In the first stage the car goes around the track, slowly mapping every cone using a SLAM algorithm. Once the whole track is mapped the driving mode is switched to a more aggressive driving style that minimizes lap time.
The goal for this project was to integrate a controller that would take care of this aggressive driving once the map of the whole track was known. To do so we built on the work of https://autorally.github.io/ with the MPPI (Model Path Predictive Integral) controller which allows for very aggressive driving at the limits of handling. The controller works by sampling thousands of potential future trajectories assigning each trajectory a cost and then using the Monte Carlo method for finding the optimal one. In this process we can take advantage of the highly parallel nature of the GPU to sample thousands of trajectories in real time while using a nonlinear dynamics model of the car.
This project was originally written using CUDA, and I set out to find out how this could be ported to SYCL and integrate this with our current stack since the original code was developed for the ROS1 framework. The reason we chose SYCL was to have a free choice of the GPU for our autonomous car and not to be tied in with CUDA compatible devices, it also gives us the ability to write the kernel code in purely standard ISO C++.
This is a short clip of the MPPI controller running in our simulation EUFS sim. We made the MPPI controller open source if you want to have a look at the code.
Porting From CUDA to SYCL
As someone who has never programmed using CUDA or SYCL I was a bit skeptical at first about whether I would be able to port the code from CUDA to SYCL and at the same time make sure the controller is compatible with our system. However, since most of the grunt work for the CUDA implementation was done for me, my job was a bit easier. I did however still needed to understand what was going on in the code, and since all CUDA documentation seemed quite daunting, I chose to look into parallel programming with SYCL first and then examine the CUDA code. However unintuitive this might seem, I feel like this approach was great and helped me get up to speed with parallel programming with both CUDA and SYCL in a matter of weeks (at least to the extent I needed to).
Once I felt confident with the APIs, I started looking into how I could translate the code. I knew translating everything manually would take a lot of time, but thankfully by using the SYCLomatic (open source) project most of the CUDA to SYCL translation can be done automatically. There were still some things that the compatibility tool could not properly translate and that was where most of the work was put in in terms of the translation. Some of the issues I had to deal with were inconsistent contexts between kernels that were using the same USM, the lack of an equivalent to CUDA textures in SYCL and me being oblivious to the fact that sycl::queue has shared pointer members which are objects with virtual destructors which are not permitted in SYCL kernels because they imply deallocating memory.
Making sure all kernels use the same contexts was easy, and it just needed a bit of extra code. The part that required a bit more work was moving away from CUDA textures into a list representation of an image. This was required for a costmap that is passed to the controller to define the track (area of low cost) for the car. Since CUDA textures are normalized I had to add some transforms for recovering the cost from the list representation of the image however this was nothing more than a bit of linear algebra. I am aware of sycl::image however I had no need for multiple channels, and I felt more comfortable using a list representation at the time. This is however something that we might change on the controller further down the line if the need for other channels for the costamp arises. My final issue with sycl::queues having shared pointer members was a bit of a tricky one since it took me a while to figure out where the virtual destructor was coming from since I had no virtual methods in my code. However, once that was located it was easy to work around by creating kernel safe classes that contained kernel functions and pointers to GPU memory without containing any sycl::queue members. In hindsight all these issues were issues that could have been easily resolved in a short time had I had more experience and knowledge about the SYCL framework.
Achieving Performance
With the controller implemented in both SYCL and CUDA I wanted to evaluate if we had lost any performance by switching from CUDA to SYCL. To do this I used the NVIDIA Nsight Systems profiler and then I compared the execution times of 3 kernels. The rolloutKernel which takes care of the trajectory sample creation and subsequently trajectory cost assignment, and then the normExp and weightedReduction kernels take care of normalizing the costs and reducing controls from the numerous samples.
To my surprise all of the SYCL kernels were initially quite a bit slower than their CUDA equivalents.
However it turned out that I made a very subtle mistake regarding the dimensions of those kernels, and that is, I kept the dimensions same as they would be in CUDA. Whereas in CUDA the threads <0,5,7> and <1,5,7> would be neighbors in the same wrap and would be accessing adjacent portions of global memory in SYCL they might not even be in the same wrap. This meant that neighboring threads weren’t accessing adjacent portions of memory and so the memory access wasn’t coalesced. Which resulted in it being slow. The good part about this is that this problem isn’t too hard to fix.
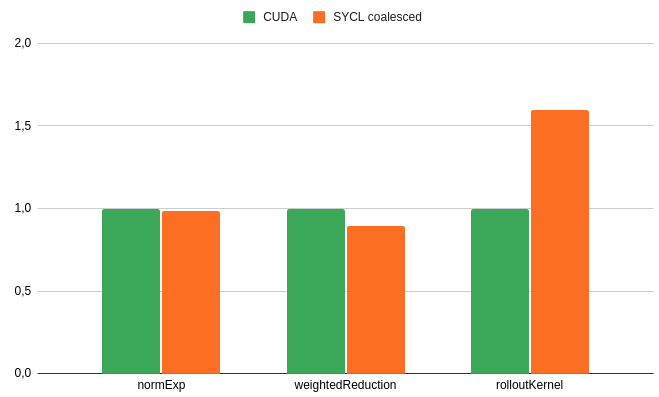
40 minutes later all kernels have been sped up with the normExp and weightedReduction kernels actually being faster in SYCL than in CUDA. The rolloutKernel was also significantly faster than previously (~40%) however it was still a lot slower than the CUDA implementation.
Using Nsight Compute I found out that the SYCL implementation was moving around a lot more data in memory and it was using Local memory which could suggest that some registers were spilling which could be causing this performance difference.
From our perspective as a formula student team this performance difference was not something that we were too worried about since we could afford the slower computation times (4.5ms with SYCL 2.8ms with CUDA). I’m still curious as to why this performance difference was present however I had to move on to other projects within the EUFS team but we hope to spend more time on this in the future.
My CUDA to SYCL Journey
As someone who has never touched CUDA or SYCL before and has never done any parallel computing this has been an incredibly fun yet challenging project and a great learning experience. When I started working on this project I was frightened by the sheer scale and complexity of the project, however it was much more straightforward than I expected and I’m hoping we can get some real world testing out of this controller soon. I hope that the team at EUFS can build on the work I have done to build even better and faster code in the future.
Lastly I would like to give a huge shoutout to Joe Todd and Rod Burns from Codeplay for the enormous support they provided during this project.
Take a look at our open source code project, and find out more about EUFS on our website.
