Big Bad Graphs and OpenCL
23 April 2021
In my IWOCL'21 presentation, "Executing Graphs with OpenCL", I argued that an execution graph must be visible to the OpenCL runtime for the OpenCL runtime to be able to schedule the graph to a graph accelerator device. I spent some time explaining how the OpenCL API represents execution graphs, and I showed some execution graphs that I extracted from the OpenCL runtime as it was executing a machine learning (ML) application. Many people are concerned that the OpenCL API cannot be used to describe graphs, and it therefore cannot be used with graph accelerators. My main goal in putting together the IWOCL presentation was to address this concern. In the limited time I had available, I showed examples of "good" graphs---graphs that have features that a graph accelerator could potentially leverage to improve performance.
There is, however, another side to the issue that didn't fit into the presentation: "bad" graphs. What does a "bad" graph look like? What makes a graph "bad"? Do bad graphs exist in the real world, or are they something I invented for the presentation?
Figure 1: A “good” OpenCL execution graph
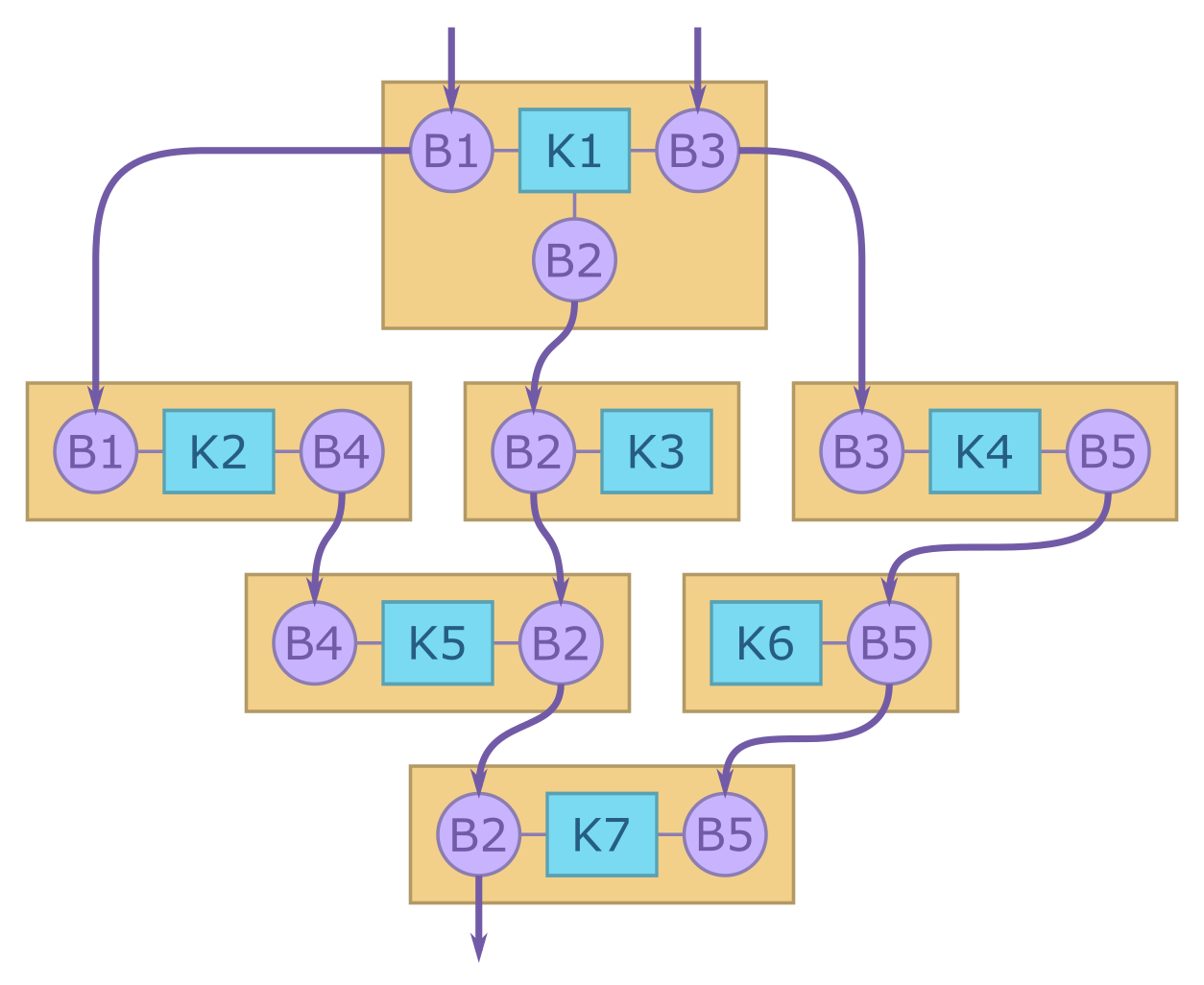
Before considering "bad" graphs, let's recap what a graph looks like to the OpenCL API and what some of the features of a "good" graph are. Figure 1 shows a fictitious execution graph. It has kernels (functions) K1 - K7 and memory buffers B1 - B5. The kernels operate on the memory buffers, as shown by the orange boxes. E.g., when K1 executes, it accesses B1, B2, and B3. K1 must use B1 before K2 can use B1. The application writes to buffers B1 and B3 via the OpenCL API before any kernels are executed. These are the inputs to the graph. The application reads from buffer B2 via the OpenCL API after the last kernel is executed. This is the output of the graph. The other buffers are only used on the accelerator device, and their contents may not be visible to the application at all.
There are two key features in this graph that are important to graph accelerators. First, K2, K3, and K4 don't have any data dependencies between them, so the OpenCL runtime is allowed to execute them in any order or in parallel. The same applies to K5 and K6. Graph accelerator devices often have many independent execution units, and executing work in parallel is key to achieving good performance. Second, B1 is first used by K1 and then by K2. If K1 and K2 are scheduled to physically different execution units, then the OpenCL runtime has the information necessary to move the data from K1's memory to K2's memory at the right time.
Figure 2: A “bad” OpenCL execution graph
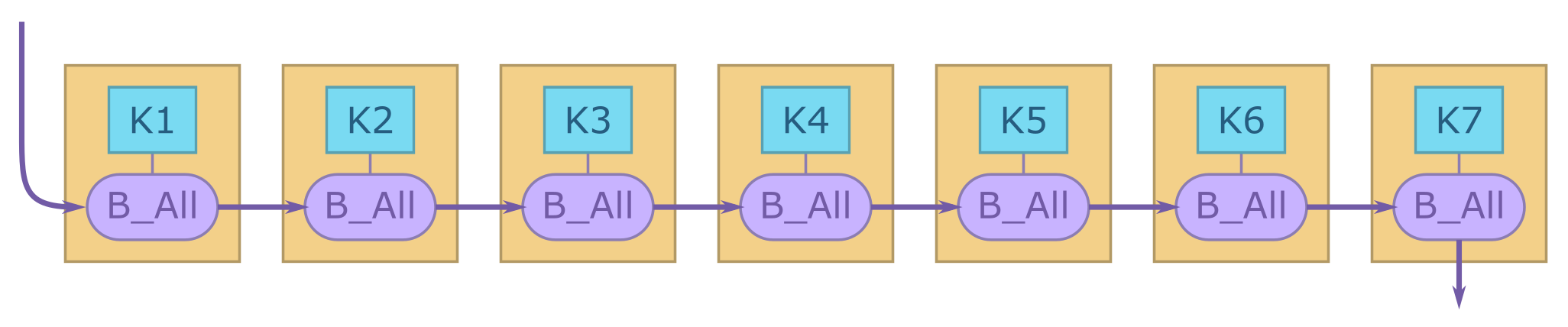
Now, consider the fictitious "bad" graph in figure 2. The graph has the same number of kernels, but the developer has decided to store all the data in a single, unified buffer. B1 - B5 from figure 1 have been concatenated into B_All. The graphs in figure 1 and 2 could well be functionally equivalent. In figure 1, K1 operates on all the data in B1, B2, and B3, but in figure 2, K1 operates on only some of the data in B_All (the data that corresponds to B1, B2, and B3).
For a more traditional, GPU-like accelerator device, the graph in figure 2 is not necessarily a problem. All the data could be placed into a global memory buffer. Since there is only one execution pipeline, the kernels necessarily execute in sequence, and each kernel accesses the relevant data in global memory. For a graph accelerator, however, figure 2 poses problems. Graph accelerators improve performance by running kernels in parallel, but the use of B_All introduces a false dependency between kernels, so the kernels must be run sequentially. Graph accelerators also leverage small, distributed memories. The individual buffers, B1 - B5, might fit into these, but the combined B_All might not. As a result, figure 2 is likely to run much slower than figure 1 on a graph accelerator.
More fundamentally, graph accelerators are designed to accelerate the execution of complicated graphs. Using a graph accelerator to run graphs like the one in figure 2 defeats the purpose of designing the accelerator in the first place.
One example of real software that produces execution graphs like in figure 2 is the OpenCL backend to the Glow compiler from Pytorch. You can see the single memory buffer's declaration here. I'm not aware of any technical reason for why Glow would be limited to using only one memory buffer, so it's possible that this may be improved in the future.
In the IWOCL presentation, I showed some "good" graphs, and in this blog post, I've explained more details about what a "bad" graph is and where one can come from. One of the key problems associated with graph accelerators is communicating the graph that an ML library user implicitly wants to execute down through the API stack to the accelerator. In the case of Glow, it's the ML compiler's backend that disrupts this chain of communication. The chain could also be disrupted elsewhere, including inside the OpenCL runtime itself. If the OpenCL runtime is not implemented to take advantage of the graph execution features of the accelerator, then the benefits of the graph accelerator will be lost even if OpenCL receives a "good" graph. The developers of each layer of the software stack have a responsibility to ensure that all the relevant information that the layer receives from the layer above is communicated to the layer below.
