Implementing OpenCL Support for Eigen using SYCL and ComputeCpp
22 May 2017
The Eigen library is probably the most popular C++-based, high-performance dense linear algebra library. It implements matrix and vector operations, geometric transformations, numerical solvers, and related algorithms. Eigen uses template metaprogramming techniques to allow developers to express complex linear algebra in a domain-specific language (DSL). The DSL allows expression trees to be built at compile-time, and used to process data at run-time. The Eigen tensor (n-dimensional array) operations are used as part of the TensorFlow framework along with other Eigen operations.
The library benefits from acceleration using heterogeneous hardware, since matrix and vector operations require many parallel calculations and are thus suited to parallellzation on GPUs. Until now, the Eigen library only supported CPUs and NVIDIA CUDA® graphics processors, limiting the hardware options for developers. Codeplay has added OpenCL™ hardware support to Eigen, to offer a wider range of hardware to developers via the SYCL™ open standard.
SYCL is a royalty-free, cross-platform C++ abstraction layer that builds on the underlying concepts, portability and efficiency of OpenCL, while adding the ease-of-use and flexibility of modern C++11/14. For example, SYCL enables single-source development, where C++ template functions are compiled for both host and device to construct complex algorithms that use OpenCL acceleration, and then re-use them throughout their source code on different types of data.
In this post we will talk about how we implemented the SYCL backend for Eigen to enable support for OpenCL hardware. If you would like to see how to get started with the SYCL implementation of Eigen, see our separate post.
Expression Trees in Eigen
Expression trees are used to represent the operations in Eigen, such as the one in the diagram below. Terminal (blue) nodes represent data items, whereas non-terminal (green) nodes are the operations that are performed on them. The operation represented below would then become a single node in a much larger TensorFlow graph that represents the machine learning model.
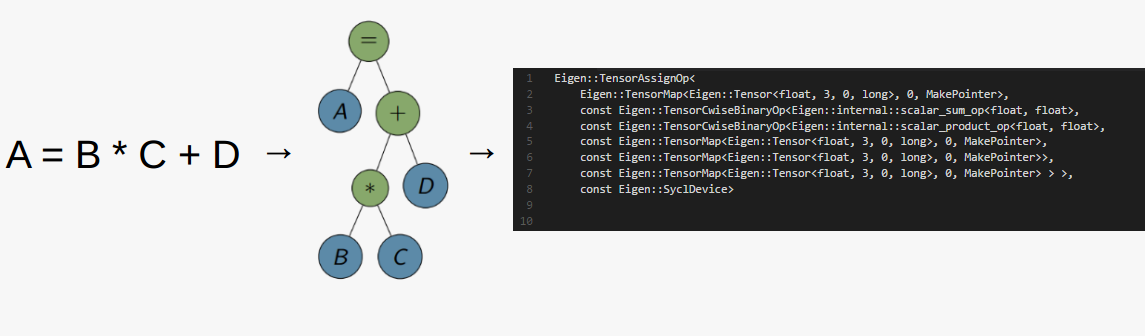
Figure: The calculation is represented as an expression tree that looks like this in the code
Kernel Fusion and Eigen
The following example calculation utilizing 3 kernels is bandwidth-bound due to the low complexity of the operations on the data, compared to the overhead of accessing it. Since there are dependencies between kernel 3 and kernels 1 and 2, there is an overhead of memory movement and setup before and after each kernel executes, so fusing the operations into a single kernel can increase the overall performance. Eigen provides an implementation of kernel fusion that gives us the ability to combine multiple kernels into one, enabling better performance than other libraries.
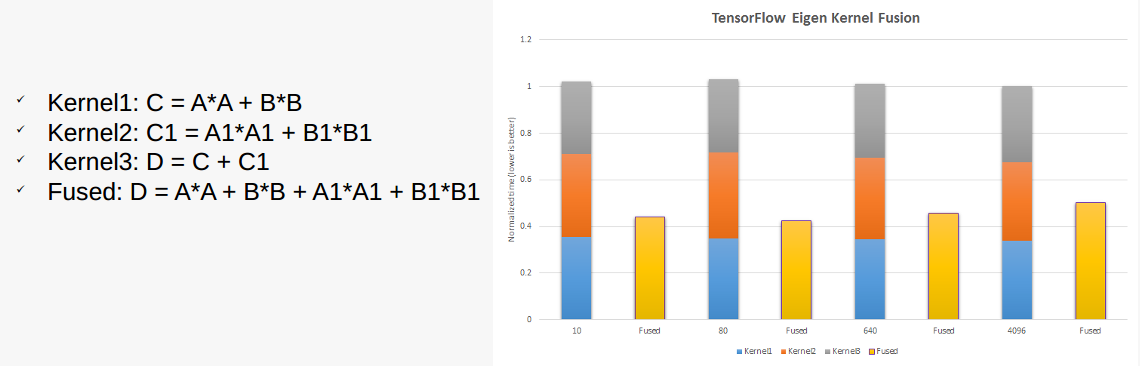
Figure: Kernel performance using individual kernels versus kernel fusion
Adding the SYCL Backend to Eigen
When we began designing the integration of SYCL with Eigen, we wanted to ensure that the back-end implementation provided compatibility for existing frameworks that use the tensor operations. By following the existing device specification we have avoided changing the interface of the existing Eigen code, meaning that all applications (including TensorFlow applications) will continue to work seamlessly with the SYCL Eigen implementation.
We also wanted to minimize the runtime overhead of applications running with our implementation, and by pushing the expression specification to compile-time as much as possible we have been able to do this, resulting in a significant speed up.
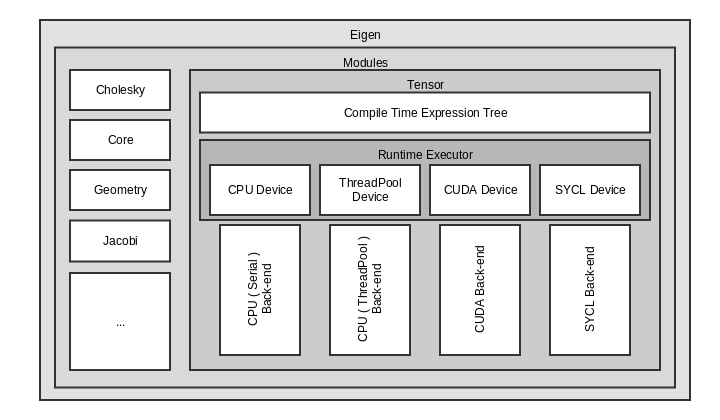
Figure: Schematic view of the SYCL backend
Challenges
The main challenge is a non-intrusive integration of SYCL into the standard C++-based Eigen code base without requiring major changes to existing code and interfaces. Targeting OpenCL 1.2 through SYCL enables Eigen to run on many low-power and mobile devices that don't support C++ operations such as direct access to host memory. This however requires the application to manage the data accessed by the kernel so integrating this with the Eigen framework in a non-disruptive way poses interesting technical challenges.
OpenCL 1.2 vs CUDA Memory Allocation
In OpenCL 1.2, memory allocations such as buffers are represented by opaque cl_mem handles on the host side. As an opaque object, address arithmetic cannot be performed on cl_mem handles. Inside an OpenCL 1.2 kernel, memory allocations are represented by pointers annotated with the address space of the allocation or variable.
However, the representation in CUDA is different. In CUDA, allocating a device buffer through cudaMalloc returns a void * pointer which is indistinguishable from a standard CPU pointer. This pointer cannot be de-referenced by the host processor, but address arithmetic can be performed (after casting to the pointer type that allows pointer arithmetic). On the device side, the CUDA compiler implicitly tracks the address space of pointers internally, without the need for programmer intervention.
In short, while CUDA uses the same types to represent memory allocations on both the CPU and GPU, and can perform address arithmetic in both cases, OpenCL uses unique representations in each case, which requires the use of explicit address spaces, and address arithmetic can only be performed on the device side.
In Eigen the CUDA backend can utilize the result of cudaMalloc directly as the data container in terminal nodes. This representation is automatically valid on the device, with no additional transformations required. However, for OpenCL 1.2 we need two different representations of the expression tree (one for host and one for device) as due to the two different representations of the memory. Therefore, it is necessary to convert the host representation of an expression to a valid device representation. In order to reduce the run-time overhead, we apply the expression conversion as a compile-time transformation.
Eigen provides a pluggable interface for the allocation and deallocation of memory. The allocation method accepts the required allocation size as a parameter and returns a void * pointer. In order to use the same interface here, we map each OpenCL memory object to a proxy host address. From the users point of view, the returned pointer can be used in an identical manner to CUDA's host-side pointer. When we convert the host expression representation to the device-side representation, these proxy addresses can be replaced with the corresponding OpenCL memory objects. Similarly for deallocating memory, we locate the corresponding OpenCL memory object based on it's proxy address and release the memory.
Initial Performance Results
The evaluation of the proposed approach was carried out on a single machine with an Intel® Core™ i7-6700K CPU, running at 4.00 GHz, with 32Gb of RAM. The GPU used was an AMD R9 Nano.
The following is a logarithmic-scale performance comparison of the Eigen operations registered for SYCL with those registered for the CPU, based on a 4k input data size.
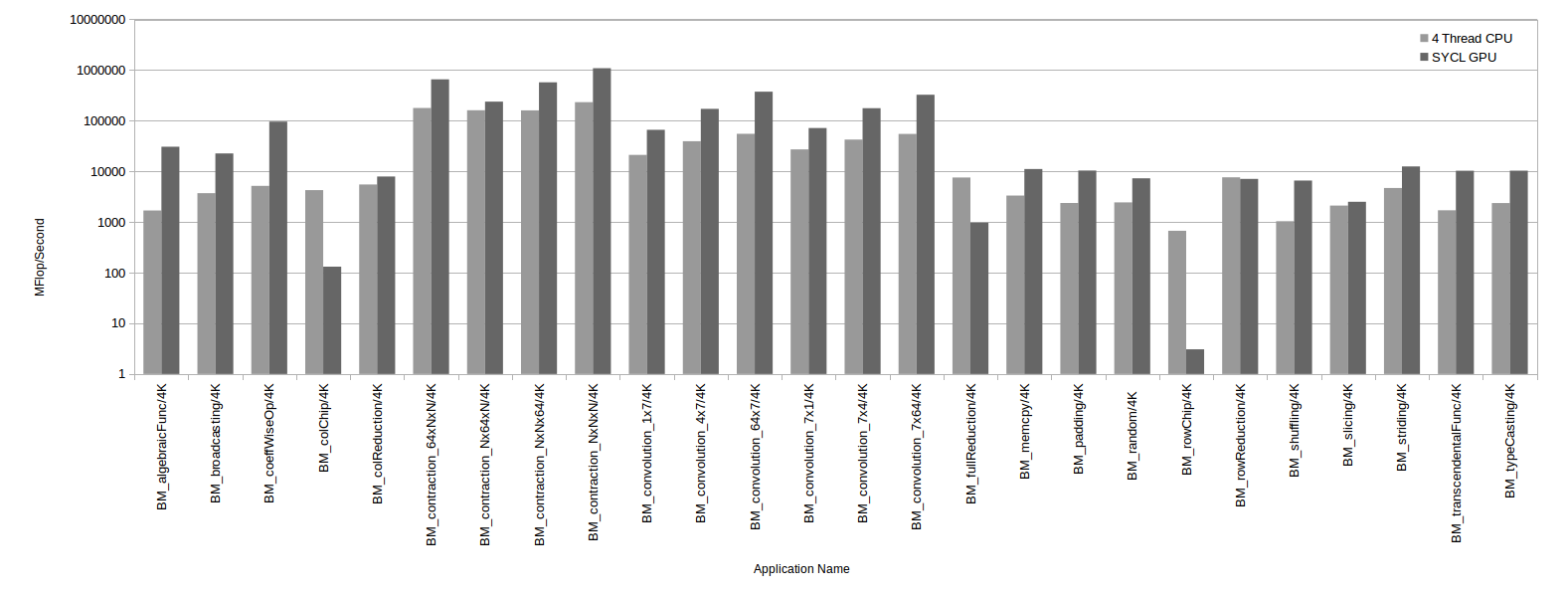
Figure: Performance of Eigen operations using SYCL on a GPU and on a quad-core CPU
We can see that there are cases such as algebraic functions, convolutions, and contractions where we have achieved up to an order-of-magnitude speed-up with SYCL.
The current version of the Eigen codebase contains the initial release of the SYCL backend, and we are continuing to optimize the performance of many of the operations.
The full paper is available to download from the ACM Digital Library, click here to download.
