
Leader in Heterogeneous Compute Software Standards and Applied Research
- Enhancing Performance Portability
- Enabling RISC-V® Accelerators in HPC
- Optimizing High Level Compiler in MLIR
Enhancing Performance Portability
With increasing heterogeneity in processor hardware, it is very crucial to be able to run the same code across different architectures. Even more important is to be able to port the applications without loss of performance. SYCL is a C++ based heterogenous programming model which has many compiler implementations and hence supports a wide variety of hardware platforms. It becomes imperative to write kernels which can achieve good performance on all these different platforms.
SYCL-BLAS and SYCL-DNN show an approach of writing modular SYCL kernels based on template meta programming. These kernels are templated on various hardware specific parameters like tile sizes, work group size, cache line size, etc. When deploying the code on a new hardware, these parameters can be tuned to achieve best performance.
email Contact Us About This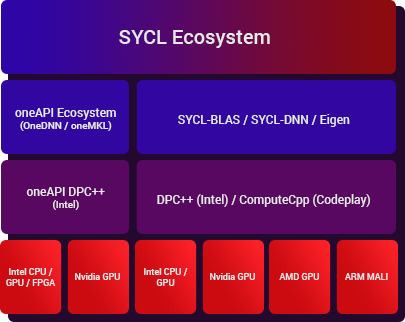
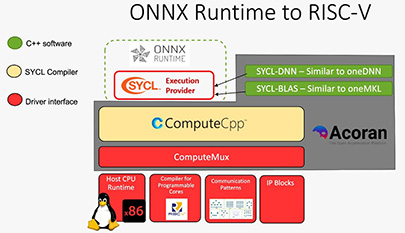
Enabling RISC-V® Accelerators in HPC
RISC-V architecture provides a modular design of layered and extensible ISA. It provides flexibility to customize processors for a specific functionality. However, programming model support for RISC-V accelerators has been minimal due to its initial stages. At Codeplay, we provide an open standard way of offloading kernels to RISC-V accelerators using the Acoran stack. The Acoran stack consists of ComputeMUX which provides the driver interface required to run SYCL code on RISC-V cores, ComputeCPP which is a SYCL compiler and SYCL-BLAS and SYCL-DNN libraries which contain optimized kernels for common neural network operations. This architecture allows for running neural network ONNX models (with the SYCL backend for ONNX Runtime) on RISC-V accelerators.
email Contact Us About ThisHigh Level Compiler Optimizations in MLIR
Integrating of Codeplay’s leading SYCL compiler/runtime with the most recent open source MLIR version to provide a tool with a more flexible way of reasoning about programs so they can be more easily ported to different architectures. The implementation will be able to explore efficiently the space of possible transformations, without having to change the source of the program, so the tool can adapt it to better fit the hardware capabilities.
email Contact Us About This